Mixed Attraction
A Song Mixed Using Data On Race And Attraction
This song was created using data on race and attraction among heterosexual couples on OkCupid, a popular online dating website. At any given time, the song's percussion and vocals are controlled by the attraction (or lack thereof) between two racial groups. In a perfect world where sexual preference is "color-blind", the resulting song would be monotonous and repetitive. Since the world is not perfect, the song is very dynamic with contrasting elements, which highlights the disparities of attraction between different racial groups in the context of online dating and beyond. The goal is to give the listener a visceral reaction to the unevenness of the data.
The Song
Listen to the song by using the player above, or check out the song on Soundcloud if you prefer no visuals or would like to comment on a specific part of the song. Read further down to learn more about how the song was constructed.
About The Data
OkCupid, a popular online dating website, recently published a blog post that explores data on race and attraction among heterosexual couples over 6 years. Here is an overview of their methodology:
- OkCupid attempts to measure your compatibility with others which they call your "Match Percentage". This is based on answering a series of user-submitted questions regarding what makes a person attractive to an individual.
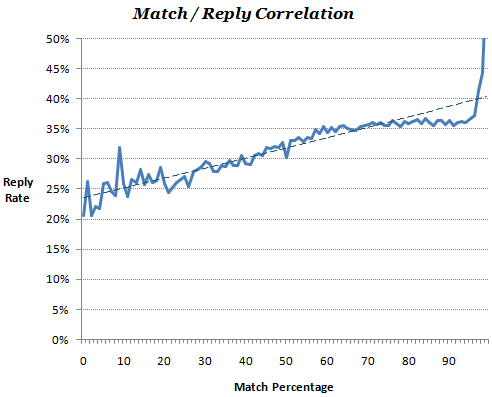
- OkCupid states that reply rate correlates to matching, in that high Match scores will result in more replies.
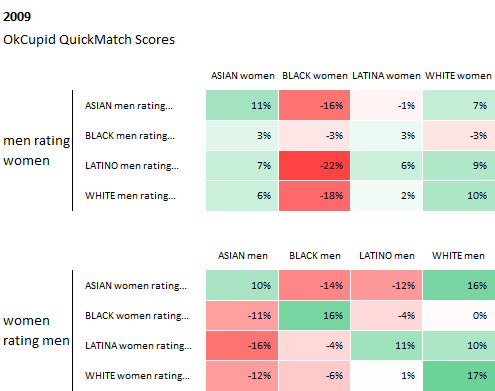
 Source: How Your Race Affects The Messages You Get, OkTrends, 2009
Source: How Your Race Affects The Messages You Get, OkTrends, 2009
- Races all match each other roughly evenly, meaning that all other things being equal, two people, of whatever race, should have the same chance to have a successful relationship.
- Therefore, you can compare the actual reply rates with the expected reply rates (from the Match score) to observe possible bias.
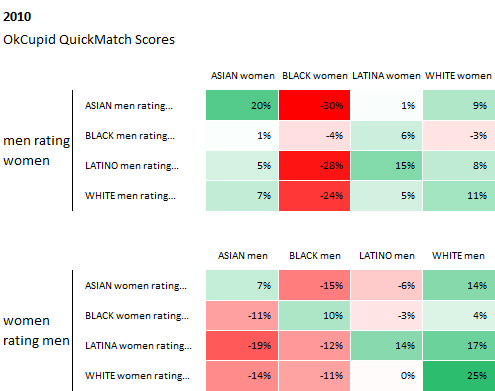
And here are their findings from "millions of interactions" of their users over the past 6 years, which indeed show that race plays a significant factor in users' reply rates:
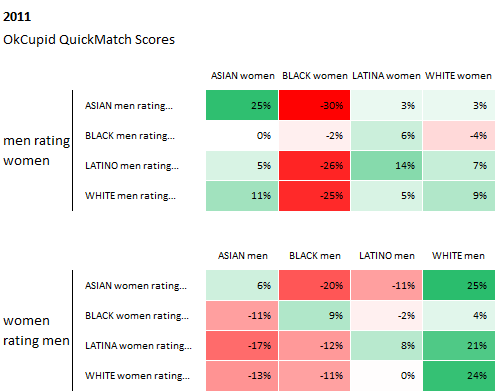
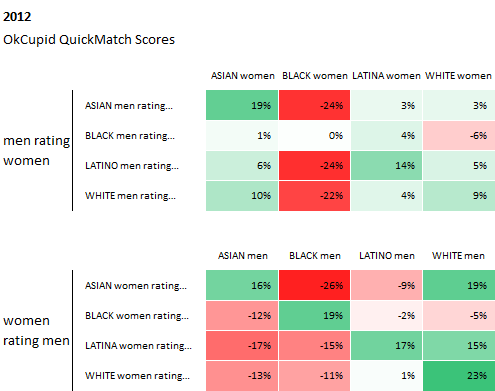
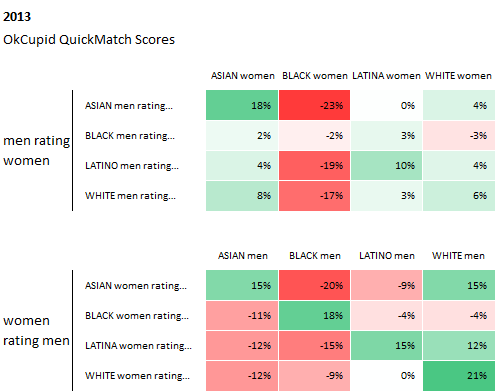

Source: Race and Attraction, 2009 – 2014, OkTrends, 2014
From OkCupid's article: The values in these tables are "preference vs. the average." Think of them as how people weigh race in deciding attraction. In a perfect world, all the boxes would have no color and contain values of 0%, indicating no bias.
Song Composition
The song composition is entirely algorithmic and is composed primarily of the data on race and attraction described above. This is how the data was used to create the song:
The song is broken up into sixteen six-second segments, one for each gender-race combination:
| White Female +White Male | White Female +Black Male | White Female +Latino Male | White Female +Asian Male |
| Black Female +White Male | Black Female +Black Male | Black Female +Latino Male | Black Female +Asian Male |
| Latina Female +White Male | Latina Female +Black Male | Latina Female +Latino Male | Latina Female +Asian Male |
| Asian Female +White Male | Asian Female +Black Male | Asian Female +Latino Male | Asian Female +Asian Male |
Each segment looks at the attraction, or more specifically the reply rates, between the two gender-race groups. Here is how the data affects the song's sounds:
| When in the data... | The result in the song is... |
|---|---|
| Female group is attracted to male group | Female vocals increase in quantity and intensity |
| Male group is attracted to female group | Male vocals increase in quantity and intensity |
| Overall attraction between groups is higher | Percussion increases in quantity and intensity |
| There is a discrepancy in attraction between two groups, e.g. the male group is highly attracted to the female group, but the female group does not reciprocate | Reverberation (reflecting or echoing sound) is added to the vocals to give the sense of space and distance |
Sounds Used
This song exclusively samples records produced by the Motown record company, who helped bring R&B/Soul to a mainstream audience in the 1960s and '70s. I thought that using classic Motown songs about love and attraction would be most appropriate for this subject. I specifically looked for vocal samples that featured cathartic grunts , whoo's , shrieks , sighs , and suggestive phrases to further emphasize the fact that the data represents sexual attraction that we may or may not be able to control. The sources of all samples are listed below:
- Vocals , Piano , Strings , and Percussion from Ain't No Mountain High Enough , an R&B/soul song and 1967 hit single performed by Marvin Gaye and Tammi Terrell. This version was inducted into the Grammy Hall of Fame in 1999, and is regarded today as one of the most important records ever released by Motown.
- Vocals from Ain't No Mountain High Enough performed by Diana Ross, recorded in 1969. This slower, gospel-like version of the popular song became Ross' first solo number-one hit on the Billboard Hot 100 chart and was nominated for a Grammy Award.
- Vocals from Let's Get It On , a song and hit single by Marvin Gaye released in 1973. The song became Gaye's most successful single for Motown and one of his most well-known songs, reaching number-one on the Billboard Pop Singles chart.
- Vocals from Love Hangover , the fourth number one single for Diana Ross recorded in 1975. It was released in March 1976, and rose to number one on the Billboard Hot 100.
Tools & Process
This song was algorithmically generated in that I wrote a computer program that took data and music samples as input and generated the song as output. I did not manually compose any part of this song.
For those interested in replicating, adapting, or extending my process, all of the code and sound files is open source and can be found here. It also contains a comprehensive README to guide you through the setup and configuration. The following is a brief outline of my process:
- Based on the project's objective, I decided upon a stylistic and compositional approach.
- I then extracted individual instrument and vocal samples from the R&B/Soul songs.
-
Using Python, a widely used programming language, I:
- Created 16 pairs of gender-race combinations and assigned an attraction value to each based on the data.
- Assigned vocals and instruments to each group based on the attraction value.
- Assigned a reverb value on vocals based on the relative attraction of each pair.
- Generated a sequence of sounds that correlate to the calculations made in previous steps.
- The sequence of sounds from the previous step was fed into ChucK, a programming language for real-time sound synthesis and music creation. I used ChucK because it is really good at generating strongly-timed sequences. The output would then be an audio file that I could listen to.
- I then repeated the previous steps numerous times, tweaking the sounds and the algorithms until I was satisfied with the result
- I used Processing, a programming language with a visual focus, to generate the visualization using the data above.
If you happen to use my code and create something new, please shoot me an email at hello@brianfoo.com. I'd love to see and share your work!
Questions & Feedback
I'd love to hear from you. I'm sure I've also made some erroneous statements somewhere, so please correct me. You can use the widget below or email me at hello@brianfoo.com.
Data-Driven DJ is a series of music experiments that combine data, algorithms, and borrowed sounds.
My goal is to explore new experiences around data consumption beyond the written and visual forms by taking advantage of music's temporal nature and capacity to alter one's mood. Topics will range from social and cultural to health and environmental.
Each song will be made out in the open: the creative process will be documented and published online, and all custom software written will be open-source. Stealing, extending, and remixing are inevitable, welcome, and encouraged. Check out the FAQs for more information.
About me
 My name is Brian Foo and I am a programmer and visual artist living and working in New York City. Learn more about what I do on my personal website. You can also follow my work on Twitter, Facebook, Soundcloud, or Vimeo.
My name is Brian Foo and I am a programmer and visual artist living and working in New York City. Learn more about what I do on my personal website. You can also follow my work on Twitter, Facebook, Soundcloud, or Vimeo.